Postgresql monitoring with Odarix
Okmeter собирает данные обо всех частях и особенностях работы Postgres. Полноценное решение, чтобы всегда быть в курсе текущей производительности работы базы данных. Детализация Okmeter позволит вам быстро выяснять причины любых проблем работы Postgres — как внутренних, так и вызванных клиентским трафиком.
Okmeter поможет вам всегда знать, что происходит с Postgres.
Окметр предоставляет детальную статистику про следующие аспекты работы Postgres
- Выполнение запросов
- Клиентские соединения
- Автовакуум
- Фоновая запись изменений и чекпоинты
- Использование ресурсов процессора и памяти
- Работа буферов и разделяемой памяти
- Использование диска
- Эффективность и использование индексов
- Блокировки и ожидания
- Операции по таблицам
- Обработка транзакций
Авто-обнаружение Postgresql
Агент okmeter имеет встроенное автоматическое обнаружение и мониторинг postgresql. По работающим на сервере процессам агент находит все запущенные экземпляры постгреса и сразу начинает снимать с каждого подробные метрики. Для получения метрик агенту необходимо наличие специальной роли в базе данных, которой предоставлены только права на чтение только системных view (pg_stat_*), что исключает доступ агента к другим таблицам вашей базы данных.
Так как на одном сервере может работать несколько экземпляров postgresql, для идентификации всем метрикам постгреc помимо метки source_hostname, по которой можно определить с какого сервера собраны показатели, добавляется еще и метка instance, которая определяет конкретный PG инстанс на сервере.
Если постгрес запущен просто как сервис, вне контейнера, то в эту метку instance проставляется IP:PORT соответствующего listen сокета инстанса. А если postgresql запущен в контейнере, то метка instance будет содержать имя этого контейнера.
Мониторинг запросов
Основная задача любой базы данных — исполнение запросов пользователей и приложений. Для обработки каждого запроса база использует ресурсы сервера:
- практически любой запрос создает нагрузку на чтение с дисковой подсистемы
- фильтрация данных, сортировки и другие стадии запроса тратят процессорное время
- INSERT/UPDATE запросы ( и некоторые SELECT) порождают операции записи на диск
- какой-то запрос утилизировал все имеющееся процессорное время, из-за чего время выполнения других запросов существенно увеличилось
- деградация сервера: понижение частоты процессора из-за перегрева или отключение write cache из-за проблем RAID
- утилизация значительного количества ресурсов сервера другими процессами: бекап, ротация логов, итд
- postgresql.query.time.total {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
- Суммарное время выполнения группы запросов. Для простоты можно считать, что время выполнения запроса складывается из ожидания ответа дисковой подсистемы, времени выполнения вычислений (процессорное время) и времени ожидания различных блокировок.
- postgresql.query.time.disk_read {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
- Суммарное время ожидания выполнения операций чтения с диска группой запросов (см. track_io_timing).
- postgresql.query.time.disk_write {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
- Суммарное время ожидания выполнения операции записи на диск группой запросов (см. track_io_timing). Но так как модификация данных в postgresql почти всегда асинхронна по отношению к запросу, нагрузку на запись нужно оценивать по другим метрикам (см. postgresql.query.blocks.dirtied)
- postgresql.query.time.cpu {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Использование процессорного времени группой запросов. Данная метрика является разницей суммарного времени использованного базой на обработку таких запросов и времени ожидания дисковых операции. Это допущение может давать ошибку при значительном времени ожидания блокировок и в случае использования параллельного seq scan в запросе.
На практике же эта метрика позволяет легко определять запросы, создавшие дополнительную вычислительную нагрузку на сервер БД: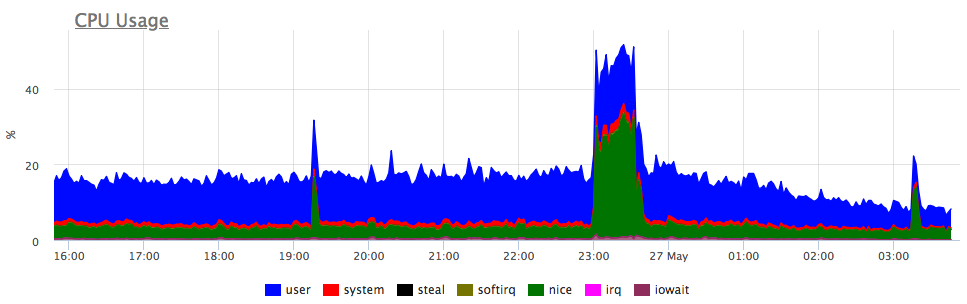
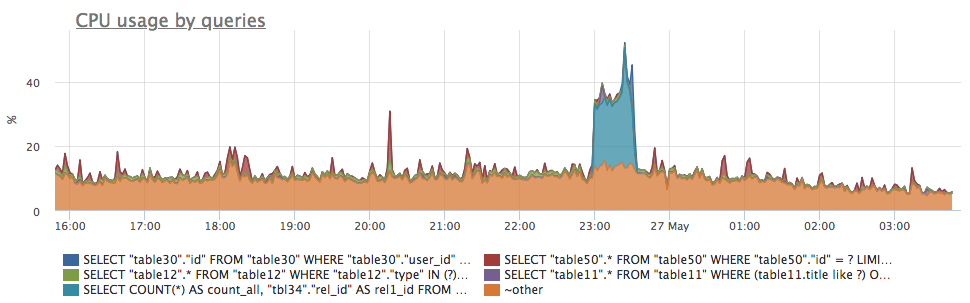
- postgresql.query.calls {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Суммарное количество вызовов данной группы запросов. По этой метрике удобно оценивать, есть ли аномалии в обычном профиле нагрузки:
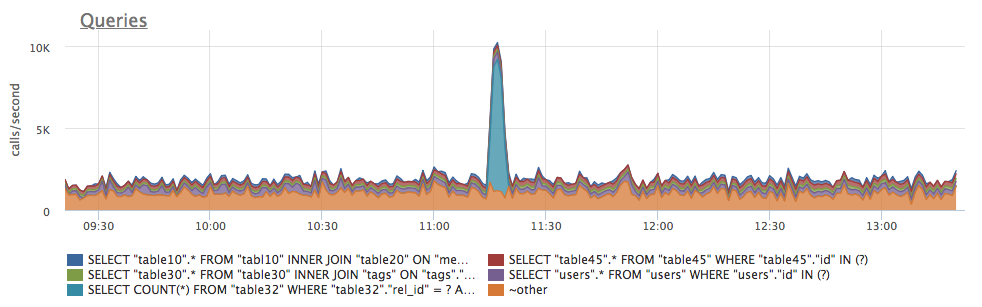
- postgresql.query.rows {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Суммарное количество строк возвращенное клиенту данной группы запросов (или измененных в ходе INSERT/UPDATE). Данная метрика позволяет косвенно узнать, какие запросы вызвали повышенные трафик на сервере БД (точного счетчика сетевого трафика для каждой группы запросов в postgresql нет):
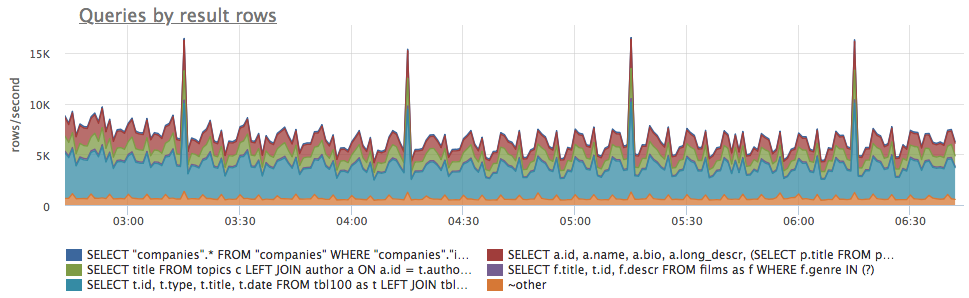
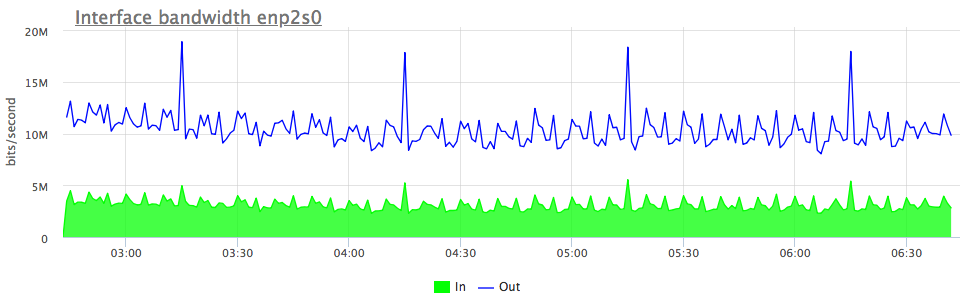 Если разделить эту метрику на количество вызовов конкретной группы запросов — postgresql.query.calls:
Если разделить эту метрику на количество вызовов конкретной группы запросов — postgresql.query.calls:
То получится среднее количество строк в ответ на один запрос (для каждой группы запросов). По этим данным легко выявлять запросы с аномально высоким количеством строк результата, как например, запросы в которых "потерян" LIMIT:metric(name="postgresql.query.rows") / metric(name="postgresql.query.calls")
- postgresql.query.temp_blocks.read {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
- postgresql.query.temp_blocks.written {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Количество блоков временных файлов, считанных или записанных группой запросов. Если набор данных, который pg считывает в ходе запроса, превышает ограничение work_mem, данные сохраняются на диск во временные файлы.
Естественно скорость выполнения запроса при этом падает, а нагрузка на дисковую подсистему возрастает. Данная метрика позволяет отследить, есть ли на вашем сервере такие запросы. В результате можно либо увеличить work_mem, либо перенести такие запросы на специальную реплику, чтобы не создавать дополнительную нагрузку на диск OLTP базы данных.

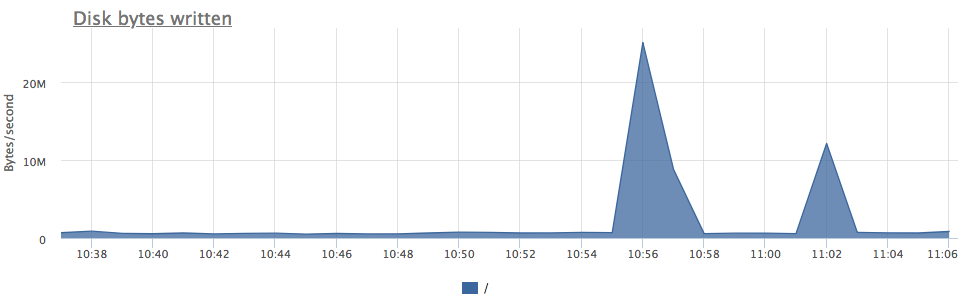
- postgresql.query.blocks.hit {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
- Количество блоков (страниц), считанных из buffer cache группой запросов.
- postgresql.query.blocks.read {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Количество блоков (страниц), считанных с диска группой запросов.
Если запрашиваемой страницы данных не нашлось в buffer cache постгреса, то postgres прочитает ее с диска. Эта метрика показывает количество таких ситуаций.
Однако такая страница данных может оказаться в page cache операционной системы, и фактический запрос чтения до диска в этом случае не дойдёт. По этой причине не стоит ожидать точного совпадения этих метрик, собранных из БД, и метрик процессов в операционной системе. Тем не менее на практике эта метрика позволяет легко определять запросы, создавшие дополнительную нагрузку на диски сервера БД:
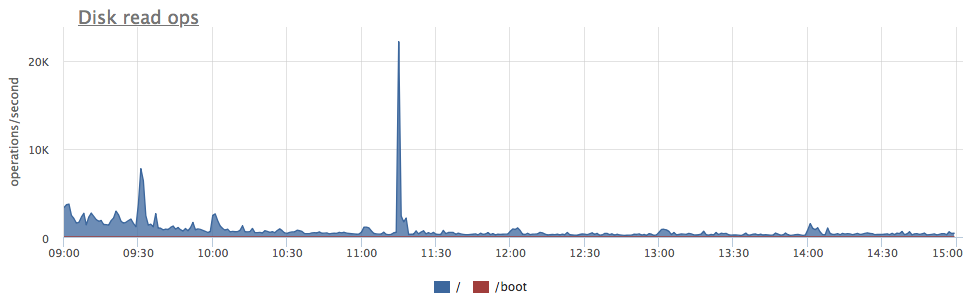
- postgresql.query.blocks.written {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
- Количество блоков (страниц), записанных на диск группой запросов. Данная метрика считает только те операции записи, которые происходили синхронно "бекендом" постгреса, прямо во время выполнения запроса. Такая ситуация бывает очень редко, т.ч. postgresql.query.blocks.written будет чаще всего нулевым.
- postgresql.query.blocks.dirtied {query: “Q”, database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Количество блоков (страниц), измененных группой запросов. В нормальной ситуации почти все изменения данных в postgresql будут записаны на диск асинхронно, уже после обработки и завершения запроса. В ходе запроса почти всегда происходит только запись изменений в WAL и изменяются страницы в памяти (buffer cache). И уже потом специальный процесс bgwriter/checkpointer записывает измененные страницы на диск.
Таким образом понять, какие запросы порождают (пусть и асинхронно) запись страниц данных на диск, можно по метрике количесва измененных запросом блоков. Хотя профиль фактической записи на диск вероятно будет значительно отличаться:
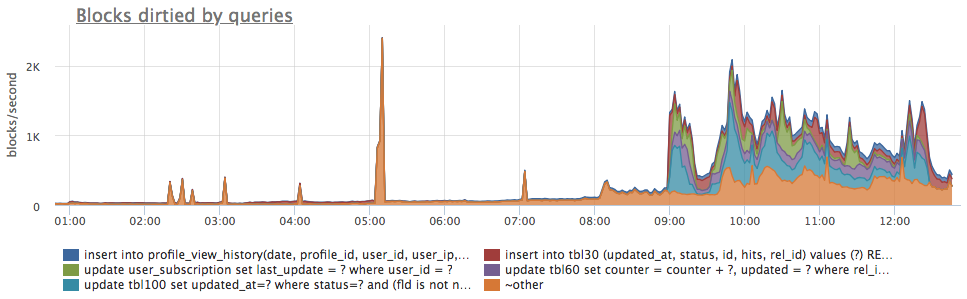

Мониторинг клиентских соединений
- postgresql.connections.count {database: "D", state: "S", client_ip: "IP", instance: “Y”, source_hostname: “Z”}
-
Количество соединений к различным базам данных с различных IP адресов в различных состояниях.
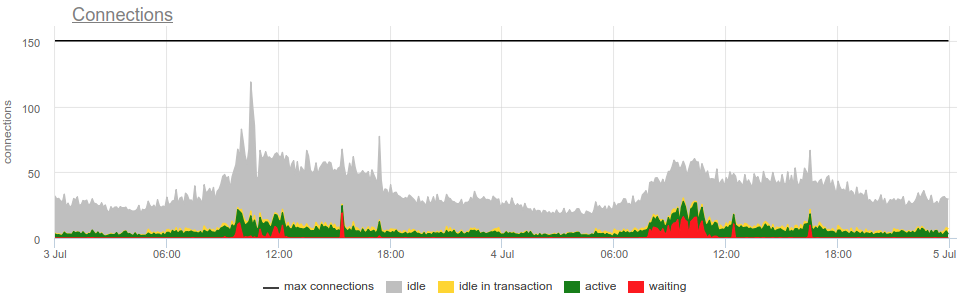 Соединения могут быть в таких (метка state) состояниях :
Соединения могут быть в таких (метка state) состояниях :
- idle — соединение в данный момент не выполняет никаких запросов.
- idle in transaction — в данном соединении открыта транзакция, но в данный момент никакого запроса не выполняется. Работающие продолжительное время транзакции не только занимают "ценные" соединения с postgresql, но и могут вызывать "распухание" БД на диске (table bloat). Отдельно стоит отметить, что при проектировании приложений стоит избегать походов по сети к другим сервисам в пределах открытой транзакции в базе данных, так как при проблемах с удаленным сервисом будет возникать большое количество соединений в состоянии idle in transaction. Postgresql начиная с версии 9.6 позволяет установить таймаут на нахождении соединения в данном состоянии idle_in_transaction_session_timeout.
- active — клиент в данный момент выполняет запрос в данном соединении.
- waiting — запрос ожидает освобождения блокировки, взятой другим запросом. Большое количество соединений в состоянии waiting как является проблемой, например если в БД продолжительное время происходит запрос, модифицирующий схему БД (ALTER TABLE). В okmeter есть преднастроенный триггер для такого случая, чтобы в момент проблем вы смогли быстро обратить внимание на подобную проблему.
- postgresql.settings.max_connections {instance: “Y”, source_hostname: “Z”}
- Текущее значение настройки postgresql max_connections — ограничения на максимальное количество соединений. Каждое соединение в postgresql это отдельный процесс, который может использовать значительный объем памяти. Количество таких соединений ограничено этой настройкой для защиты от ситуации, когда клиенты открывают слишком много соединений к постгреc и таким образом могут израсходовать всю доступную память. Данная метрика позволяет не только всегда знать значение данного параметра и отслеживать изменения, но так же дает возможность сравнить текущее количество открытых соединений с этим лимитом. Okmeter уведомит вас, если количество открытых соединений подбирается к ограничению.
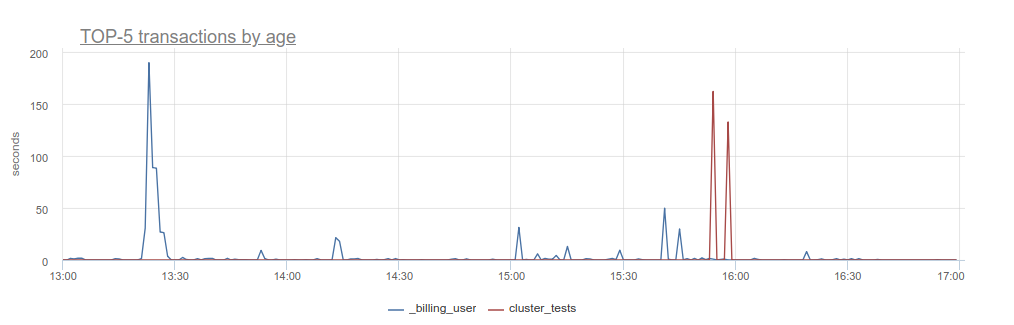
- postgresql.connections.max_transaction_age {database: "D", user: "U", instance: “Y”, source_hostname: “Z”}
-
Длительность самой "старой" транзакции к каждой базе данных по каждому пользователю. Данная метрика позволяет отследить "зависшие" транзакции и понять, какой пользователь их запустил.
Мониторинг автовакуума
Для обеспечения транзакциональной целостности данных postgresql использует модель MVCC. Согласно этой модели каждая запись данных может существовать в нескольких версиях, для каждой из которых определена область видимости — интервал номеров транзакций [xmin, xmax], в котором запись видна/доступна.
Из-за такого подхода у postgresql возникают следующие задачи:
- Удаление устаревших записей — когда какая-то запись была удалена или изменена (т.е. создана ее новая версия), то в какой-то момент все работающие транзакции, которые могли были видеть предыдущую версию, завершатся. После этого данная версия больше не нужна, т.к. никогда больше не будет прочитана. И ее стоит и нужно удалить для освобождения места на диске.
- Защита счетчика транзакций от переполнения (a.k.a. wraparound) — в postgresql счетчик транзакций — это int32, который сбрасывается при достижении максимального значения данного типа. Это может нарушить процесс вычисления видимости версий, опирающийся на попадании текущего номера транзакции в интервал видимости [xmin, xmax] записи.
- postgresql.settings.autovacuum_max_workers {instance: “Y”, source_hostname: “Z”}
- Текущее значение настройки postgresql autovacuum_max_workers — ограничения на количество одновременно работающих процессов autovacuum.
-
postgresql.autovacuum_workers.common {instance: “Y”, source_hostname: “Z”}
postgresql.autovacuum_workers.wraparound {instance: “Y”, source_hostname: “Z”} -
Текущее количество работающих процессов autovacuum c разделением по типу обрабатываемой задачи:
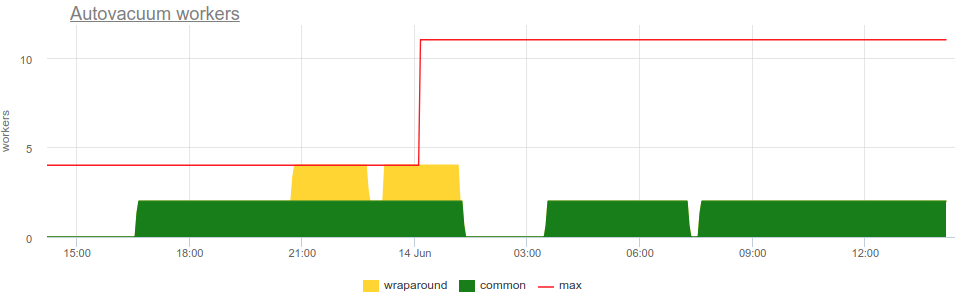
- wraparound — количество таких воркеров автовакуума, работающих в данный момент. Wraparound воркер помечает достаточно старые версии записей спец-флагом frozen, чтобы предотвратить проблемы при сбросе счетчика транзакций.
- common — количество "обычных" воркеров автовакуума. Такой воркер ищет и удаляет устаревшие и уже ненужные версий записей.
- postgresql.table.autovacuum_count.rate {table: "T", database: "D", instance: “Y”, source_hostname: “Z”}
-
Количество проходов autovacuum для каждой таблицы.
 По этому графику легко понять, работой с какими таблицами были заняты процессы autovacuum.
По этому графику легко понять, работой с какими таблицами были заняты процессы autovacuum.
- postgresql.db.transactions_left_before_shutdown {database: "D", instance: “Y”, source_hostname: “Z”}
-
Количество транзакций, оставшихся до принудительной остановки postgresql из-за угрозы потери данных по причине transaction ID wraparound.
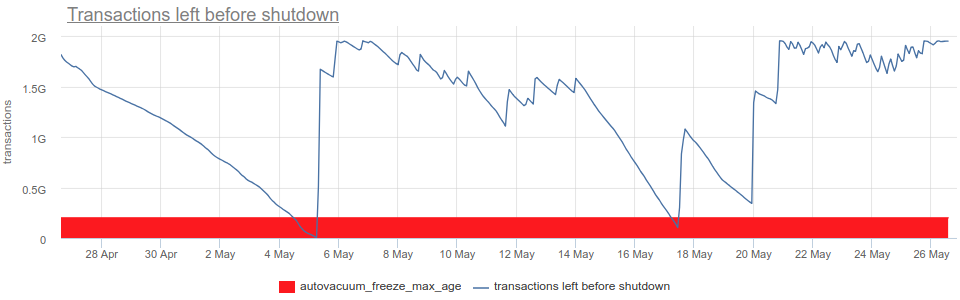
Если текущее значение будет меньше, чем autovacuum_freeze_max_age, постгреc принудительно запустит autovacuum, даже если он выключен в настройках.
Тем не менее даже принудительный автовакуум может не успеть исправить ситуацию, и если значение transactions_left_before_shutdown упадет ниже 10 млн (константа в коде postgresql), на каждую транзанкцию postgres начнет выдавать предупреждение вида:
WARNING: database "db1" must be vacuumed within 9999999 transactions HINT: To avoid a database shutdown, execute a database-wide VACUUM in that database. You might also need to commit or roll back old prepared transactions, or drop stale replication slots.Если же данная метрика опустится до 0, все попытки начать новую транзакцию будут завершаться ошибкой:ERROR: database is not accepting commands to avoid wraparound data loss in database "db1", HINT: Stop the postmaster and vacuum that database in single-user mode. You might also need to commit or roll back old prepared transactions, or drop stale replication slots.В такой ситуации только superuser базы сможет как-то исправить ситуацию вручную, например, запустив vacuum.
Okmeter поможет вам избежать такой опасной ситуации — автоматически и заранее уведомит вас, чтобы было время со всем разобраться!
Мониторинг background writer
Bgwriter это специальный процесс Postgres, который в фоне записывает, синхронизует страницы с измененными данными на диск, чтобы процессам, которые обрабатывают запросы, не приходилось ждать такой синхронизации.
В Postgres попытка сделать COMMIT транзакции завершится успешно, когда все изменения данных записаны в WAL. Одновременно с записью в WAL данные изменяются и в памяти — в shared buffer'ах. Но почти всегда эти страницы с измененными данными не записываются на диск сразу, а помечаются флагом dirtied, чтобы быть записанными на диск в фоне.
В случае аварийного завершения postgresql до того, как все такие "грязные", dirty страницы были записаны на диск, информация об изменениях восстанавливается из данных WAL в процессе recovery. "Грязные" страницы могут быть записаны на диск либо в ходе операции CHECKPOINT, либо в ходе работы bgwriter (background writer), либо прямо во время обработки какого-то запроса. Для отслеживания этих процессов есть следующие метрики:
- postgresql.bgwriter.buffers_checkpoint {instance: “Y”, source_hostname: “Z”}
- Количество буферов, записанных в ходе чекпоинта.
- postgresql.bgwriter.buffers_backend {instance: “Y”, source_hostname: “Z”}
- Количество буферов, записанных в ходе запроса. Такое может происходить, если нужной страницы нет в shared buffers, а страница-кандидат на вытеснение "грязная". В этом случае бэкенд должен записать на диск эту страницу и только потом продолжить работу (подробнее об этом читайте в нашем блоге). Если вы увидели, что значительное количество записи производиться бэкендом, можно попробовать настроить bgwriter на более интенсивный режим работы.
- postgresql.bgwriter.buffers_clean {instance: “Y”, source_hostname: “Z”}
-
Количество буферов, записанных в ходе работы bgwriter (background writer). Данный процесс занимается записью на диск "грязных" редко используемых страниц.
Bgwriter позволяет снизить количество записи при checkpoint и может снизить количество записи в ходе запросов (buffers_backend).
Если все этим метрики вывести на график, можно понять, в какой момент какой именно процесс вызвал запись: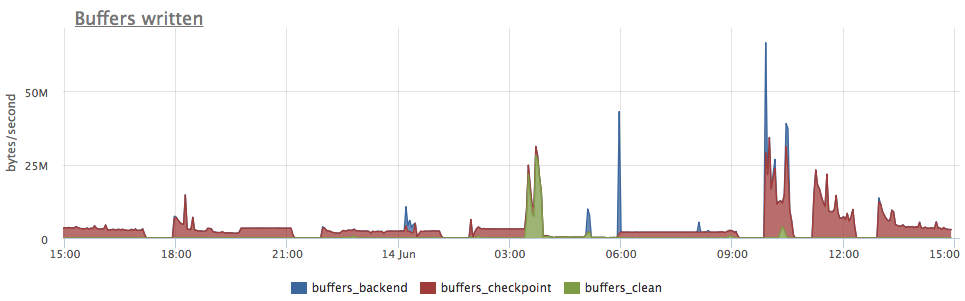
- postgresql.settings.bgwriter_lru_maxpages {instance: “Y”, source_hostname: “Z”}
- Текущее значение настройки postgresql bgwriter_lru_maxpages, которая позволяет ограничивать нагрузку на диск, создаваемую bgwriter.
- postgresql.bgwriter.maxwritten_clean {instance: “Y”, source_hostname: “Z”}
- Количество раз, которые bgwriter прекращал работу из-за превышения bgwriter_lru_maxpages. Если же вы хотите увеличить интенсивность работы bgwriter, то метрика maxwritten_clean поможет понять, нужно ли увеличивать bgwriter_lru_maxpages, или в этом нет необходимости.
Мониторинг checkpoint'ов
Checkpoint это специальный процесс, в ходе которого все dirty страницы записываются на диск, а текущая позиция WAL помечается, как отправная точка для возможного recovery. Это нужно для того, чтобы для восстановления базы не приходилось "проигрывать" весь WAL целиком.
Чекпоинт может быть запущен в нескольких случаях:
- Запуск администратором команды CHECKPOINT, либо утилитами управления БД — создание базы данных, backup и т.п.
- По срабатыванию checkpoint_timeout — если за определенный интервал чекпоинт ни разу не запускался.
- По размеру WAL'а накопленного с последнего чекпоинта — max_wal_size или, для версии < 9.5, по количеству накопленных сегментов лога — checkpoint_segments.
- postgresql.bgwriter.checkpoints_timed {instance: “Y”, source_hostname: “Z”}
- Количество работающих чекпоинтов, инициированных по срабатыванию таймаута.
- postgresql.bgwriter.checkpoints_req {instance: “Y”, source_hostname: “Z”}
-
Количество работающих чекпоинтов, инициированных по условию на размер накопленного WAL.
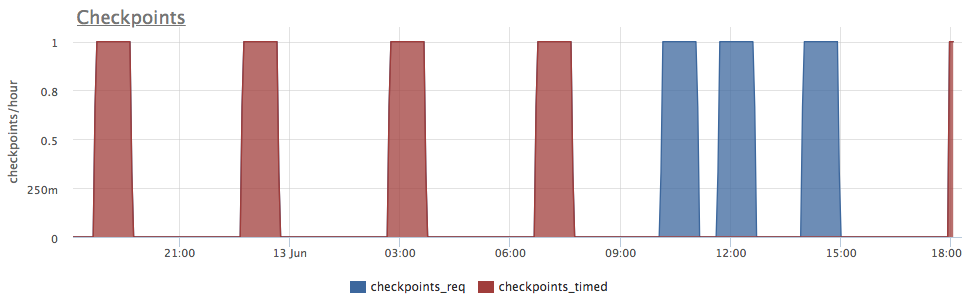 Например, на данном графике видно, что до 9:00 чекпоинты запускаются по таймауту раз в 4 часа — когда, судя по предыдущему графику, нагрузка на запись была невысокая. А примерно с 10:00 часов чекпоинты начинают запускаться чаще по срабатыванию условия на размер WAL, что согласуется с большим количеством записанных буферов на предыдущем графике.
Например, на данном графике видно, что до 9:00 чекпоинты запускаются по таймауту раз в 4 часа — когда, судя по предыдущему графику, нагрузка на запись была невысокая. А примерно с 10:00 часов чекпоинты начинают запускаться чаще по срабатыванию условия на размер WAL, что согласуется с большим количеством записанных буферов на предыдущем графике.
И это не всё!
Тут описана только некоторая часть того, с чем okmeter поможет разбираться. Кроме того okmeter.io соберет и покажет детальные метрики других аспектов работы базы данных Postgresql:
- Использование ресурсов процессора и памяти
- Работа буферов и разделяемой памяти
- Использование диска
- Эффективность и использование индексов
- Блокировки и ожидания
- Операции по таблицам
- Обработка транзакций
Мониторинг okmeter не только покажет, как сейчас работает база данных и оповестит вас о том, если что-то идет не так, но и поможет понять, что делать. С okmeter вы всегда знаете, что происходит с postgresql в каждый момент.