Process monitoring with Odarix
Okmeter снимает метрики не только про потреблении ресурсов сервера в целом, но и показывает какие процессы их утилизировали. Это позволяет не гадать, что происходило на вашем сервере в какой-то момент времени, а точно знать это.
На самом деле мы собираем метрики не про каждый процесс, а объединяем их в группы по общей части имени процесса, имени пользователя, который запустил этот процесс и названию контейнера. Каждая метрика помимо метки source_hostname с именем хоста имеет еще метки:
process— имя процессаusername— имя пользователяcontainer— имя контейнера или “~host”, если процесс запущен вне контейнера
Про каждую группу процессов okagent собирает утилизированное процессорное время данной группой процессов:
- process.cpu.user{process:”X”, username: “U”, container: “C”}
- — время проведенное процессом в userspace.
- process.cpu.system{process:”X”, username: “U”, container: “C”}
-
— ожидание выполнения системных вызовов.
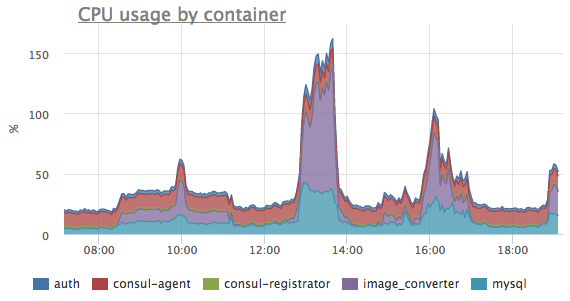
По этим метрикам очень удобно следить за тем, какие процессы больше всего нагружают какой-то конкретный сервер:

или посмотреть суммарно по кластеру, какие контейнеры больше всего нагружают процессор:
- process.mem.rss{process:”X”, username: “U”, container: “C”}
-
— размер резидентной памяти, используемой данной группой процессов.
Эта метрика позволяет выявить не только процессы, которые потребляют больше всего памяти, но и увидеть утечки памяти:

- process.mem.swap{process:”X”, username: “U”, container: “C”}
-
— использование swap группой процессов.
Полезнее смотреть не на саму эту метрику, а на ее производную - скорость прироста/убывания swap для каждого процесса. Это позволяет увидеть процессы, которые активно работают со swap, при этом их быстродействие из-за этого может быть замедленно:

В okmeter также есть автоматический триггер уровня info (без уведомления), который сработает, если любой процесс на каком-либо сервере работает со swap на скорости более 1MB/s более двух минут. Это хорошо работает как подсказка в момент проблем в вашей инфраструктуре.
Остальные метрики по процессам:
- process.proc_count{process:”X”, username: “U”, container: “C”}
- — количество процессов в группе
- process.thread_count{process:”X”, username: “U”, container: “C”}
- — суммарное количество тредов в группе
- process.disk.ops.read{process:”X”, username: “U”, container: “C”}
- — количество операций чтения с диска, выполненные данной группой процессов
- process.disk.ops.write{process:”X”, username: “U”, container: “C”}
- — количество операций записи на диск группой процессов
- process.disk.bytes.read{process:”X”, username: “U”, container: “C”}
- — количество байт, считанных с диска группой процессов
- process.disk.bytes.write{process:”X”, username: “U”, container: “C”}
-
— количество байт, записанных на диск группой процессов

- process.open_files.count{process:”X”, username: “U”, container: “C”}
- — количество файловых дескрипторов открытых группой процессов
- process.open_files.max_usage_percent{process:”X”, username: “U”, container: “C”}
-
— процент использования открытых файловых дескрипторов относительно лимита
ulimit -nдля каждого процесса — берется максимальный процент из группы процессов.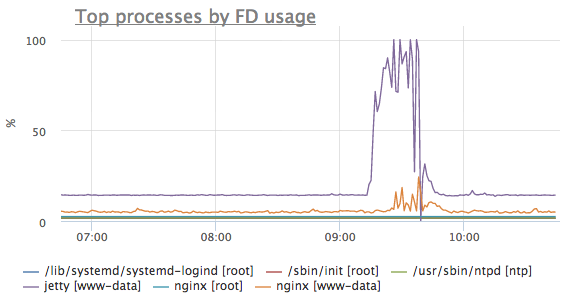
Для этой метрики есть автоматический триггер, который сработает, если количество открытых дескрипторов приближается к лимиту. Если процесс достигнет этого лимита при попытке открыть файл или сетевой сокет процесс получит ошибку от ядра (too many open files), это может привести к отказу в обслуживании вашего сетевого сервиса, базы данных или других процессов.
- process.max_cpu_percent_per_thread{process:”X”, username: “U”, container: “C”}
- — процент использования процессора одним потоком процесса. Эта метрика позволяет отслеживать ситуацию, когда однопоточное приложение утилизирует одно процессорное ядро полностью, но при этом не может работать с несколькими ядрами. Например, для таких приложений как redis, pgbouncer, nginx worker - достижении этого лимита приведет к увеличению времени отклика.
- process.uptime{process:”X”, username: “U”, container: “C”}
- — максимальный uptime процессов в группе. По этой метрике можно отслеживать перезапуск процессов, например при изменении конфигурации или изменении версии.
Все этим метрики okmeter агент соберёт самостоятельно со всех процессов, без какой либо настройки. Такая детальность и степень покрытия позволяют иметь полную картину происходящего. Кроме того исторические данные позволяют разбираться с причинами уже прошедших проблем, а не гадать по поводу произошедшего.